
tiero - Fotolia
What is SRE in DevOps and how do they work together?
Site reliability engineering and DevOps share a close relationship -- but it's not always clear what, exactly, that relationship is. Walk through the basics of SRE, and its place in DevOps methodologies.

The emergence of massively scalable cloud services marked the end of an era -- and the start of a new one -- in IT. Just as Henry Ford couldn't deliver an automobile for the masses without reinventing the production process, Google couldn't provide reliable search and email services without rethinking IT operations and system design.
A fundamental feature of Google's mechanistic approach to cloud-scale operations is site reliability engineering (SRE). Much like DevOps, with which it is often conflated, SRE requires changing both organizational mindset and operational processes. SRE views site operations as part of a broader sequence of automated processes.
SRE is gaining mindshare as enterprise IT organizations look more like cloud operators through migrations to software-defined services and scalable infrastructure. With this change, IT operations and application development teams understand the value of DevOps -- and of a systematic, automated approach to IT operations as embodied by SRE.
Read on to learn the impetus for SRE -- along with its core principles and typical implementation path -- and how IT organizations can adopt it in DevOps workflows.
Why SRE is needed
Benjamin Treynor coined the term SRE and defined its principles after he became Google's head of production engineering in 2003. When asked to define SRE in an interview, Treynor replied:
SRE is fundamentally doing work that has historically been done by an operations team, but using engineers with software expertise, and banking on the fact that these engineers are inherently both predisposed to, and have the ability to, substitute automation for human labor.
Treynor has expounded on the background and principles many times, including in a seminal book on reliability engineering. In the book, Treynor explains that SRE partially arose to ease the tension between product development teams that wanted to develop and release new products and features as fast as possible, and operations teams, whose primary goal was to ensure that the service doesn't break while they are holding the pager. Because most outages result from a change -- whether a configuration update, software patch or new feature -- the two goals are inherently at odds. Treynor developed SRE to bridge the gap between these two goals. SRE treats infrastructure and operations as a software problem and replaces error-prone manual tasks with repeatable, programmatic processes.
Create an SRE organization
Treating IT operations as a software problem was a natural outgrowth of a culture and workforce like Google's, dominated by highly skilled and motivated software engineers. However, its workforce doesn't represent the majority of IT departments. This disparity increases the challenge of translating Google's SRE principles to an organization comprised of specialized system administrators who are more comfortable working within management consoles and domain-specific CLIs than a generalized software language.
In his USENIX presentation, Treynor summarized 12 points of advice for IT executives and aspiring SREs looking to enter the field:
- Create a service-level agreement (SLA) for every service.
- Measure and report performance against each SLA.
- Use error budgets -- a clear service-level objective measurement of how unreliable a service is allowed to be within a single quarter -- and make product launches contingent on them.
- Hire only coders, i.e., those with software development experience fluent in picking up new programming languages.
- Have a shared staffing pool for SRE and development functions.
- Cap the operational load of SREs at 50%. Leave half their time for engineering work that improves process automation or adds features.
- Push excess operational work -- that above the 50% cap -- to the development team.
- Share 5% of the operational work with the development team. Combined, principles 7 and 8 motivate developers to consider operational and deployment issues when they design and code their software.
- Limit on-call teams to eight people, or a maximum of two six-person teams.
- Limit on-call events to two per shift with no more than 25% of an engineer's time on-call as either the primary or secondary contact. Engineers must have adequate time to handle any incidents and follow-up activities, such as writing postmortems. If the two-incident rule is exceeded for a quarter, teams should implement corrective measures to ensure sure that the operational load returns to a sustainable state.
- Every incident must have a post-mortem write up that carefully defines incidents, as writing post-mortems costs valuable time. Valid incidents include all events that involve user-visible downtime, service or performance degradation, data loss or an on-call intervention, such as rolling back a software release, or manually reconfiguring the network or servers.
- Post-mortem reviews don't cast blame, but focus on the process and technology breakdowns. Reviews should assume that everyone involved acted in good faith and did their best under trying circumstances. Avoid blame to identify causes and fixes via a free flow of information and ideas without fear of reprisal.
What is SRE in DevOps, exactly, then?
DevOps is an overloaded term, whose imprecision leads to its overuse in ways that mask its core tenets. First and foremost, DevOps is a cultural shift that breaks down silos between development, testing, QA and operations teams to accelerate application development, improve software quality, increase infrastructure availability, maximize application performance and reduce costs. This methodology reforms organizational structures and processes and instigates subsidiary changes. For example, DevOps brings increased collaboration within and between teams, high reliance on standardized, automated processes and shared responsibility between development and operations teams for application and service quality and reliability.
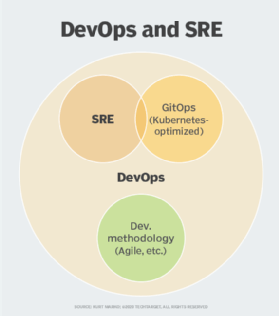
SRE takes the broad philosophy of DevOps and adds the process, standards and automation details required to run systems of massive scale and geographic distribution. SRE and DevOps are not competitors, but rather partners that work together to streamline operations, eliminate organizational silos and deliver high-quality software faster.
Editor's note: DevOps and SRE are also closely associated with GitOps, a Kubernetes-centric paradigm for application delivery.
DevOps lays the groundwork for SRE. However, not all DevOps organizations will need SRE, at least in the sense Google describes. Organizations that have entirely outsourced their IT infrastructure to cloud providers will only require a subset of SRE. In this case, engineers monitor and manage the interaction of applications and their cloud resources, and act as the contact for support escalations to their cloud providers. However, in all situations, SREs must be proficient in process automation via software development.







