12 DevOps KPIs you should track to gauge improvement
What's missing from your DevOps workflow? Cold, hard, impartial numbers. Track these key metrics to ensure DevOps processes achieve stated goals.

It's no small task to transform an IT organization to integrate development, operations and quality assurance teams. A DevOps methodology requires team and process changes and then, once everything is in place, the onus is on IT to create DevOps KPIs and measure the outcomes.
The key to a productive DevOps program is effective and comprehensive measurement and monitoring. Create a detailed game plan to understand how processes and projects work and how to improve them over time.
DevOps key performance indicators (KPIs) are complicated by the fact that this methodology has no formal framework, thus the definition of progress can vary between organizations. However, there are common metrics and KPIs that should keep a DevOps project on track.
1. Deployment frequency
Innovation begets rapid technology changes. Track code deployment frequency for a clear picture of how quickly new features and capabilities roll out. This metric should stay consistent or trend upward over time. A decrease or stutter suggests a bottleneck somewhere within the DevOps team workflow.
2. Change lead time
Determine how long it takes a change, such as a bug fix or new feature, to go from inception through dev and test to production. Long lead times could suggest inefficient processes that inhibit change implementations; short lead times can indicate a smooth DevOps process overall.
This DevOps KPI should be a starting point to discover patterns that signal complexity has caused a bottleneck in a given area.
3. Change volume
This metric goes hand-in-hand with deployment frequency, and quantifies the number of new user stories or code changes the DevOps team delivers with each release, or in a given period of time. This KPI helps measure the value of a deployment to end users and whether the team is thinking atomically about change, or is still in the mindset of big, complex deployments seen often in Waterfall development.
While a high change volume can be a sign of an effective iterative approach to the product, it can also be an indicator of too narrowly slicing the project, and changes occurring purely for the sake of change. Teams should be careful not to dedicate too much time to frequent code changes that are insignificant to their organization or end users.
4. Failed deployments
Changes must roll out smoothly, not just frequently. Keep the failure rate for application changes and releases deployed into production as low as possible. Potential failures include a change that leads to time-out problems for users, or that requires a rollback for further work. Develop a system to track the success and failure of changes. A high rate of change failure affects the application's end users and requires admins to invest additional time to troubleshoot issues and fix bugs rather than accomplish high-value initiatives.
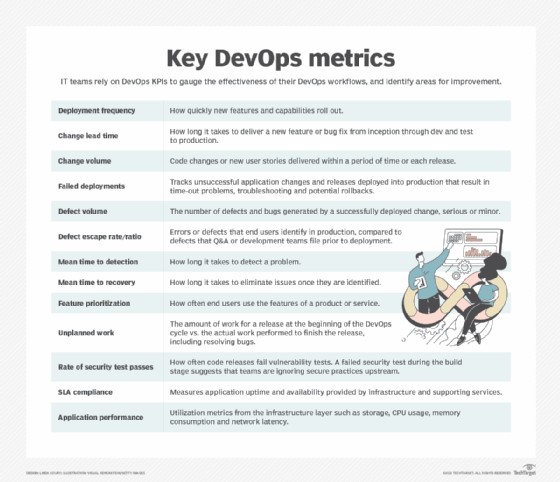
5. Defect volume and escape rate
A change might deploy successfully but generate a lot of bugs. While these errors aren't necessarily significant enough to cause an outage, they negatively affect the end-user experience. Ideally, the DevOps KPI for defect volume should remain as low as possible. However, some organizations embrace the concept of an error budget, positing that 100% uptime and reliability negatively affect app capabilities and project budgets. In its most basic form, an error budget encourages innovation and rapid iterations, with an expected tolerable level and frequency of bugs and downtime.
Also monitor the defect escape rate -- also known as the defect escape ratio. This DevOps metric represents the number of errors or defects that end users identify in production, compared to the number of defects that the quality assurance (QA) or development teams filed prior to deployment. A high defect escape rate indicates a problem with QA tests and code review.
6. Mean time to detection
Don't measure DevOps KPIs in isolation. A low change failure rate isn't good enough if it takes too long to detect a problem. For example, if the mean time to detect (MTTD) is 30 days, that means it could take a full month to diagnose an issue that causes failure rates to rise. MTTD should decrease over time as DevOps processes mature. If MTTD is high or trends upward, expect the bottlenecks causing these existing delays to introduce additional congestion into the DevOps workflow later down the road. Fast detection is a boon to security as well, as it should minimize an attack's reach.
7. Mean time to recovery
Mean time to recovery is another key DevOps metric that admins should keep as low as possible. Eliminate issues once you become aware of them. DevOps organizations follow the principle that frequent, incremental changes are easier to deploy, and easier to fix when something goes wrong. If a release includes a high degree of change and complexity, it becomes more difficult to identify and resolve issues within it.
8. Feature prioritization
How often do end users take advantage of the product's or service's features? If your DevOps team spends the time and effort to create and implement new code into production, make sure those features are valuable to the target population. BizDevOps reinforces the value of iteration to meet user demand as quickly as possible. If feature usage is low or declining, reevaluate the prioritization factors with management to determine a better feedback loop from users.
9. Unplanned work
This metric helps track both the quality of software releases, as well as the overall productivity -- and happiness -- of a DevOps team. Quantify the amount of work for a release at the beginning of the DevOps cycle, and compare that to the actual work required to finish the release. Be aware of unplanned work that gets completed, as well as work that's begun then dropped and ongoing progress beyond release.
The more time developers and operations admins spend on unplanned work, such as resolving bugs in production, the more likely there's an issue inherent in the DevOps approach. Perhaps there are insufficient testing practices, or discontinuity between the dev, test and production environments.
When teams spend a lot of time fighting unforeseen fires, overall productivity declines, and the risk of IT burnout increases.
10. Rate of security test passes
Vulnerability scanning is not a common test case within a software delivery pipeline. Determine the test's viability and implement whenever possible. A failed security test during the build phase could prevent some releases from going into production. If code releases consistently fail vulnerability tests, this DevOps KPI suggests that teams are ignoring secure practices upstream and ultimately must correct those issues.
11. SLA compliance
Application uptime is an important metric for every IT organization. Service-level agreements require that the infrastructure, services and supporting applications meet a high goal of availability. Services should be online as much as possible, which creates uptime goals as high as 99.999%.
12. Application performance
An unexpected influx of end users can create performance issues at the infrastructure layer -- it turns out you can get too much of a good thing. Storage bottlenecks, CPU spikes, high memory consumption and network latency are all common side effects of a surge in application use. Closely monitor these standard performance aspects of the servers that support an application. Increasing volumes of end users can require additional infrastructure to be built in. However, performance decreases without additional end-user requests could indicate that bugs or inefficient changes from development and release are bogging down the app. Verify and correct these as they occur to enable high availability and a good end-user experience.







