Free DownloadWhat is container management and why is it important?
Container management refers to a set of practices that govern and maintain containerization software. Container management tools automate the creation, deployment, destruction and scaling of application or systems containers. Modern Linux container technology was popularized by the Docker project in 2013, and interest soon expanded beyond containerization itself to the intricacies of how to effectively and efficiently deploy and manage containers. Use this guide to learn more about container management, including its benefits and challenges, strategies for enterprise use and prominent vendors and tools.
Master these 3 common Kubernetes troubleshooting tasks
Not enough nodes? Have some noisy neighbors? Plenty of things can cause containers to underperform. Here's how to chase down and resolve three common Kubernetes problems.
Unfortunately, it can also be a challenge to troubleshoot Kubernetes. It is one thing to recognize that a container cluster is unavailable or that a pod doesn't respond as expected. But how do IT admins figure out the cause of those issues and then fix them?
Let's look at three common Kubernetes troubleshooting scenarios that IT and DevOps teams may encounter, and how to address them.
1. Unavailable nodes
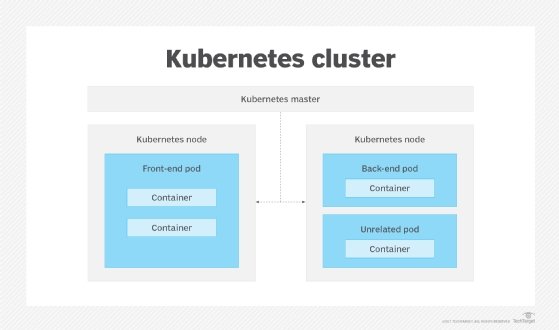
To achieve high availability for the applications it hosts, Kubernetes must be able to distribute applications across a variety of nodes, which are the physical or virtual servers that form the host infrastructure for a Kubernetes cluster. If you find that a Kubernetes cluster fails to provide the desired availability, there is likely an insufficient number of available nodes.
To troubleshoot this problem, first ensure you've assigned enough nodes to a cluster. As a rule of thumb, any cluster designed for high availability should consist of at least two dozen nodes. At least two of those should be the all-important master nodes, but more is better.
Even with a sufficient number of nodes, you may find that nodes fail after you've set up and joined them to a cluster. One way to address this issue is to enable auto-recovery of any VMs that host nodes. Most cloud providers and on-premises VM platforms offer auto-recovery features that restart a failed machine automatically.
Increasing the number of physical servers in a cluster may also improve node availability, even if the number of nodes stays the same. When you spread nodes across more physical servers, you limit the harm done to your cluster by a server failure.
2. Noisy neighbors
The so-called noisy neighbor problem, which refers to one application hogging resources in a way that deprives other applications of necessary resources, is a common challenge in a multi-tenant Kubernetes cluster.
By default, Kubernetes aims to ensure that all applications have the resources they need. Even so, Kubernetes configuration files don't always include the detail that the Kubernetes scheduler requires to achieve this goal. Kubernetes has no way to automatically determine exactly how much compute, memory or other resources an application may need at a given time. Kubernetes can't read application code itself to assess resource needs. It can act based only on resource configurations that are specified in Kubernetes configuration files.
Proper use of namespaces can also help to troubleshoot noisy neighbors in a Kubernetes cluster.
To troubleshoot Kubernetes' noisy neighbor problems, first ensure that Kubernetes is configured with the information it needs to assign the right amount of resources to each workload. Admins can do this at the level of individual containers or pods using Limit Ranges, a capability that specifies the maximum resources that a container or pod can consume.
Proper use of namespaces can also help to troubleshoot noisy neighbors in a Kubernetes cluster. Use namespaces to divide a single cluster into different virtual spaces. The Resource Quotas tool can place limits on the amount of resources that a single namespace can consume, thereby helping to prevent one namespace from using more than its fair share of resources. Keep in mind, however, that Resource Quotas apply to an entire namespace; they can't control the behavior of individual applications within the same namespace. To do that, you need Limit Ranges.
3. Non-responsive containers
In a cluster that has sufficient nodes and properly configured Limit Ranges and Resource Quotas, containers or pods may still be less responsive than they should be. This is usually due to poorly configured readiness or liveness probes.
Kubernetes uses liveness probes to check whether a container is responsive. If it's not, Kubernetes restarts the container. Readiness probes determine whether a container or set of containers is both up and ready to accept traffic.
In general, these probes are good safeguards against situations where admins need to manually restart a failed container or where containers are not yet fully initialized and therefore not ready for traffic.
Readiness and liveness probes that are too aggressive, however, can lead, somewhat paradoxically, to containers that are unavailable. For example, consider a liveness probe that checks a container every second and restarts the container if it determines that container is unresponsive. In some situations, network congestion or latency problems will cause the readiness check to take longer than one second to complete -- even if the container is running without issue. In that case, the container will be restarted constantly for no good reason, leaving it unavailable.
To prevent this, configure readiness probes and liveness probes in ways that make sense for containers and environment variables. Avoid one-size-fits-all configurations. Each container probably needs its own policies.