Server hardware guide: Architecture, products and management
Today's server platforms offer a host of options for SMBs and enterprise IT buyers; it's important to learn the essentials before making any purchasing decisions.

The explosive growth of cloud computing platforms and the preceding wave of virtualization have significantly altered the role of the server among SMBs and enterprises.
Virtualization enabled organizations to load multiple virtual machines (VMs) on a single, physical box, boosting hardware utilization and offering the ability to consolidate IT resources. Virtualization paved the way to the cloud, as IT managers were able to transfer VMs offsite to run on hyperscale providers, such as AWS, Google and Microsoft. Business-critical applications -- such as CRM, HR and ERP -- previously operating on in-house servers, also journeyed to the cloud in the form of SaaS.
That said, businesses of all sizes will continue to own and operate servers. Some organizations prefer to maintain in-house servers and private clouds for particularly sensitive workloads or applications too costly or difficult to migrate to a public cloud platform.
Read on to learn more about the different types of servers, their evolving architectures and what IT buyers should look for regarding key requirements.
Types of server hardware
The mainframes of the 1950s and 1960s can be considered the original servers, but the history of servers in the modern sense starts in the 1990s with the invention of web and rack-mounted servers. Today, servers come in a range of form factors and offer varying capabilities, finding a home in settings from small businesses to large enterprises.
The following is a rundown of some of the prevalent types of server hardware:
- Tower servers. A tower server resides in an upright, standalone cabinet, resembling a tower-style PC. These servers provide the benefit of easier cooling because they offer a relatively low component density. They are also comparatively inexpensive, making them an option for smaller businesses on a limited budget. However, tower servers take up more space than other server types.
- Rack servers. A rack server is designed to be mounted on a server rack in a data center. Rack servers often play an all-around computing role in the data center, supporting a multitude of workloads. These servers take up less space than a tower server. Rack servers and server racks are built to consistent size standards so that servers from multiple vendors can be stacked together. Standardization also makes adding new servers or replacing old ones a straightforward task for engineers. Cable management, however, can prove a challenge when maintaining rack servers, which are tethered to power supplies, networking equipment and storage devices.

- Blade servers. A blade server is a compact device that houses multiple thin, modular circuit boards called server blades. Each blade contains a single server, which is often assigned to one application. Since blade servers tend to be dedicated, admins have greater control regarding how they are accessed and how data is transferred among devices.

Blade servers offer greater processing density than other server types, providing a potential price and performance advantage. Other blade server benefits include cooling -- with each blade being cooled individually by fans -- minimal wiring, low-power use and storage consolidation. Blade server systems are also simpler to repair than rack servers due to their hot-swappable, modular components. On the downside, blade servers historically have been built on proprietary architectures, making vendor lock-in a possible pitfall for buyers.
- Hyperconverged infrastructure. HCI systems aim to provide a simpler alternative to traditional IT infrastructure, pulling together compute power, storage and hypervisor technology in an integrated system. With a typical hyperconvergence offering, a midlevel data center engineer should be able to complete the tasks of initial hardware configuration, hypervisor deployment and software-defined storage implementation in about an hour. Vendors' products offer setup wizards to gather the appropriate information. The implementation processes are mostly automated.
- Mainframes. The rise of client-server architectures in the 1990s was forecast to obliterate mainframes, but those high-end servers continue to exist. Today's mainframes offer the ability to support large volumes of simultaneous transactions and heavy I/O loads without taking a performance hit. Financial services firms conducting concurrent, real-time transactions are among the typical mainframe customers. The primary drawbacks to mainframes are their size and price tag.
Server hardware architecture
The key components of server hardware architecture include the motherboard, processor, random access memory (RAM) and storage.
The motherboard resides at the heart of the server, providing the central nexus through which system components are interconnected and external devices are attached. Advanced Technology Extended and Low Profile Extension are the main types of motherboards, with Balance Technology Extended, Pico BTX and Mini Information Technology Extended motherboards addressing the needs of smaller form factors.
The processor, or central processing unit (CPU), resides on the motherboard. CPU components include the arithmetic logic unit, floating point unit, registers and cache memory. A server might also contain a graphics processing unit (GPU), which can support applications such as machine learning and simulations. Tensor processing units and neural processing units offer additional levels of processor specialization.
RAM microchips also plug into the motherboard, serving as a system's main memory. RAM holds the OS, applications and in-use data for fast access by the processor. As for storage, a server might use a hard disk drive (HDD), a solid-state drive (SSD), the cloud or a mix.
A server's form factor, meanwhile, influences the role it will play. An enterprise data center, for example, might consider the differences between rack and blade server form factors.
An organization seeking to run a heterogenous data center might choose rack servers because various makes and models can exist together in a common physical deployment approach. Rack servers also offer a range of power connections and network cabling choices. Large rack servers also offer extensibility, accommodating additional processors, memory and local storage disks.
Blade servers, meanwhile, are geared toward single-vendor IT settings that seek to unite compute, storage and networking within a single system. The blade server approach offers the benefits of faster deployment and simplified management.
Other trends in server architecture include disaggregation and composable infrastructure, which can be viewed as a continuation of converged infrastructure. Composable infrastructure uses software-defined methods to logically pool computer, storage and network fabric resources in a data center. Those resources become the basis for shared services, which admins can draw upon to compose compute instances on the fly.
Requirements
IT buyers in the market for servers must consider a range of factors when evaluating hardware vendor offerings, bearing in mind their current and future workload needs. An organization's requirements will naturally vary but will revolve around the following server hardware features:
- CPU. The CPU is a fundamental component to review, given its role in running programs and manipulating data. Some servers run multiple processors, typically with one processor per socket. Others use a single processor consisting of multiple cores to support multiprocessing. Given those possibilities, buyers should consider the number of cores available on a processor, CPU clock speed, the available cache and the number of sockets. Vendors offer a range of product options, so the IT buyer's job becomes finding the server hardware configuration that best fits a particular environment. Organizations running cloud infrastructure in a data center, for example, can perform a variety of general-purpose computing tasks on a 0.5U single-CPU server or a 1U dual-CPU server. The relatively small 1U unit might prove a good option since it can readily accommodate 16 cores with normal data center cooling approaches. This server category also provides some flexibility when it comes to storage drives and connections.
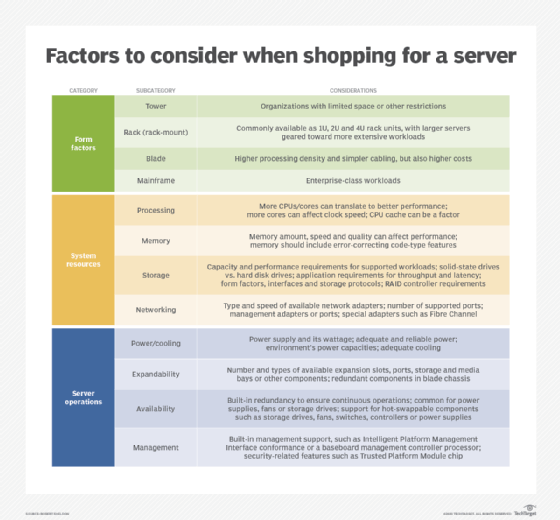
- Memory. Server memory is critical for getting the maximum performance out of a system. The higher the amount of available memory, the better an organization's workloads are likely to perform. Other factors contributing to performance include the memory's speed and quality. IT buyers should also consider server features that bolster reliability. Those include fault-tolerant capabilities and error-correcting code.
- Storage. A server's storage requirements will depend on the intended applications and workloads: A database server will have different needs than one running a web application. An IT buyer must examine server technology to make sure it meets the organization's storage requirements. Most server vendors support flash storage in the form of SSDs and traditional hard drive technology. That said, buyers should check with vendors to confirm the drive types they support as well as their supported drive technologies, which might include Serial-Attached SCSI, Serial Advanced Technology Attachment and non-volatile memory express (NVMe). The intended server workload will determine which technology is a must-have item. For instance, an organization dealing with large databases and unstructured data will generally require local instance drives, such as NVMe PCI Express units. Other factors on the server storage checklist should include drive speeds and disk space.
- Connectivity. Network connectivity and interconnects -- such as host bus adapters, which link servers to storage -- are also important server considerations. Buyers should determine their connectivity requirements and then examine a server's specifications to make sure those needs are met. Variables to evaluate include the number and speed of Ethernet connectors, the number and type of USB ports and support for storage systems, such as storage area networks.
- Other features. Additional attributes to investigate include hot-swapping capabilities and the level of redundancy available for components such as hard drives, power supply units and fans. Server management capabilities and security features are also important. Admins should also consider the general operating environment in which the new servers will reside. Keeping server temperature and humidity within recommended ranges contributes to high availability. In 2021, the American Society of Heating, Refrigerating and Air-Conditioning Engineers (ASHRAE) updated its recommended temperature and humidity ranges for data center hardware. The high end of the ASHRAE temperature range, for example, is now set at 80.6 degrees Fahrenheit. The guidelines can potentially help companies save on data center energy and electrical costs.
Management and maintenance
Managing servers and keeping them in working order encompasses a range of activities and tools.
Server monitoring systems, for example, provide critical data that admins can use to detect issues before they escalate to problems that could result in outages. Some of the essential components and tools of server monitoring include capacity management tools that track the usage of resources, such as CPU, memory and storage.
Specialized energy consumption tools, meanwhile, enable admins to gauge a server's efficiency. Tools in this category include meters embedded in uninterruptable power supplies, which report the power consumption of connected devices. Other options include external power meters, online energy consumption calculators and hardware vendors' configuration tools.
Although proper maintenance should help extend server life, hardware degradation is inevitable. A server's physical components will eventually break down, with power, temperature, management and memory among the problem areas. At some point, servers will need to be decommissioned and replaced.
At the high end of the server spectrum, proper mainframe decommissioning calls for several steps. Initially, IT managers should take inventory of the applications running on the mainframe server. The next step is to outsource the applications to a service provider specializing in mainframes or replatforming the mainframe's applications to operate on x86 servers. Admins must also create a security plan, which could include deleting the mainframe's data or destroying hard drives.
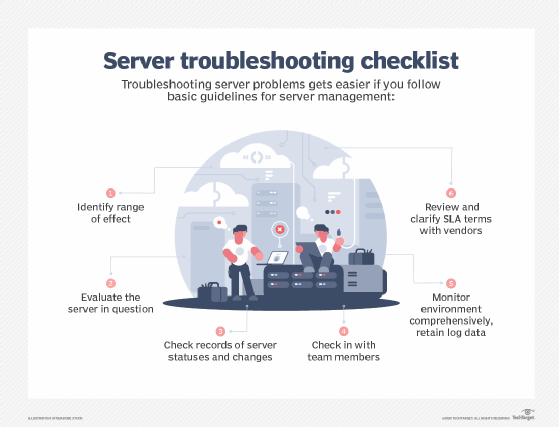
Troubleshooting
End-of-life hardware will need replacing at some point, but until then, admins must troubleshoot a server to keep it operating. An important first step is determining the scope of the problem -- who are the affected users, and are they reporting any consistent error messages? Once the problem is isolated to a particular server, admins can consult monitoring tools for alerts, check network connections and review the server environment's topology.
Troubleshooting and the use of monitoring tools can help organizations maintain system availability. But there are other steps organizations can take as they develop approaches to prevent and recover from server failure. Those include maintaining adequate server ventilation, temperature control and following a routine maintenance regimen.
Failure to update machines also ranks among the top common server hardware issues that can result in poor performance. Organizations should develop a process for regularly updating applications, firmware and OSes. Special attention should also be paid to server security and power. The latter calls for the installation of uninterruptible power supplies and the purchase and testing of on-site generators.
Vendors and products
Customers can choose from myriad options when it's time to buy a new server. Server hardware options in the rack, blade and mainframe server market include offerings from more than a dozen vendors. The list of suppliers includes the following:
- Acer. Acer's server offerings include its Altos rack systems, high-density servers and GPU servers.
- Asus. AsusTek Computer Inc. provides rack servers under the RS Series and ESC4000 Series product lines. It also offers GPU servers.
- Cisco. Cisco aims to cover customers of varying size with its UCS B-Series Blade Servers, UCS C-Series rack servers, UCS S-Series storage servers and branch-office oriented Cisco UCS X-Series servers.
- Dell. Dell provides a broad range of rack and blade servers, with offerings including its PowerEdge R-Series rack servers, PowerEdge M-Series blade servers and PowerEdge C-Series that target hyperscale data centers.
- Fujitsu. Fujitsu's offerings for U.S. customers include its Primergy rack and modular servers and the more powerful Primequest series. The company also sells mainframe servers, but buyers must be aware that available models can vary between countries.
- Hewlett Packard Enterprise. HPE rack servers include the ProLiant DL, Integrity and Superdome Flex products. Blade server offerings can be found in the ProLiant and Integrity lines.
- IBM. IBM launched the most recent version of its zSystems mainframes, z16, in 2022. Other offerings include a range of rack servers and the LinuxOne 4 system for hybrid cloud environments.
- Lenovo. Lenovo's server lineup includes its ThinkSystem rack servers and Flex System blades. The ThinkSystem line also offers edge servers for IoT and storage as well as mission-critical servers geared toward data analytics and virtualization.
- Oracle. Oracle's offerings include x86 servers, Sparc servers and Network Equipment Building System (NEBS) servers. The NEBS-compliant servers are for telecommunications and embedded-industrial settings and other uses.
- Super Micro. Super Micro Computer Inc. provides an extensive range of servers. The company's rack systems are geared toward uses from enterprise applications to in-memory computing. Other offerings include twin servers and blade servers.
Servers for small businesses
The following are a few examples of server hardware for small business customers, which tend to purchase tower servers:
- Asus. The company's TS500 machine can run as a workstation or server.
- Dell. The PowerEdge T40 entry-level server is oriented toward file, print, mail and messaging services.
- Fujitsu. The company's compact Primergy TX1310 M5 server features a screwless chassis and HDD quick-release capabilities.
- HPE. HPE's ProLiant ML350 Gen10 can be configured with a range of Xeon scalable processors.
- Lenovo. The ThinkSystem ST250 V2 is a small office server intended for business and retail applications.
Purchasing considerations
Whether you are purchasing a server for an enterprise or a small business, the fundamentals are essentially the same: Understand your requirements and use cases and match those up against the products you evaluate. Vendors offer a wide range of server form factors, configurations and models, many of which are optimized for particular types of workloads. Buyers must be willing to conduct a careful analysis or hire a consultant or channel partner, such as a value-added reseller, to identify the server that best suits their needs.
Organizations sizing up server options should also familiarize themselves with purchasing methods. Vendors sell servers on their website, through a direct sales force, using online retailers and in partnership with authorized channel companies. Some vendors use a combination of sales outlets.
Cost is always a consideration, particularly for budget-constrained organizations, such as small businesses. SMBs should consider several factors when calculating server hardware costs. The first task is to determine hardware requirements based on anticipated uses. Although this will help scope the hardware costs, buyers must also examine server OS costs, which can rival the hardware price tag, and the cost of applications intended to reside on the server. Also factor server maintenance and administration costs into the total cost of ownership equation.
The future of server hardware
The future of server hardware must be viewed in the context of cloud computing and its growing influence. The cloud has become very popular among businesses. A report from Zippia shows that 94% of enterprises and 67% of enterprise infrastructure use cloud services. This quick adoption of cloud servers and services is partly due to the COVID-19 pandemic, causing businesses to move more workloads to cloud platforms as a business resiliency measure.
Small business and corporate data centers, however, will continue to own and operate servers, often as part of hybrid cloud environments. Outside of those organizations, service providers will likely hold sway as the key server buyers.
Servers will remain important, but how the technology is consumed will continue to change, especially with a push toward green data centers.
Editor's note: Vendors and products were chosen based on what companies have server hardware options and the likelihood a company, small or large, would use these servers. This list has been modified to show updated vendors that sell server hardware options as of 2024.
John Moore is a writer for TechTarget Editorial covering the CIO role, economic trends and the IT services industry.






