
twobee - Fotolia
Why is high availability important in cloud computing?
How many "nines" does your own cloud app really need? High availability is still an important factor in a cloud SLA, but uptime needs vary for each service and company.

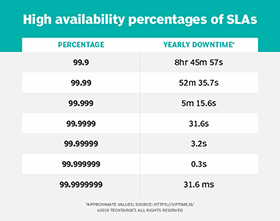
When it comes to high availability in cloud computing, companies love to shoot for the moon. Vendors list three, four and five "nines" when marketing downtime, so it can be difficult for IT teams to determine how much uptime they actually require for their own applications.
Google, Amazon and Microsoft all have service level agreements (SLAs) of at least 99.9% availability (three nines) for each paid service, but no more than 99.99% (four nines). For perspective, 99.9% availability means just shy of nine hours of downtime in a year and 99.99% means less than an hour of downtime in a single year.
When IT pros talk about a service being highly available, this is what they're referring to. The major cloud providers can fulfill the relatively high bar in these agreements, despite the complexities involved, thanks to armies of talented engineers and decades of established processes.
The typical enterprise can't replicate that, but it doesn't mean that your customers or stakeholders will let unnecessary downtime slide. You need a well-reasoned SLA that dictates your application's availability, and it all starts with understanding the complexity of your app.
For example, a simple static website can easily expect to achieve four nines or more of uptime, because there are few potential points of failure. Yes, there's the web server and the machine it is running on, but with the addition of a floating IP address, a load balancer and a redundant server, it would be rare if you experienced any preventable downtime.
Now, consider a more complex, monolithic web application. While four nines may still be possible, the pressure to achieve it increases as you add components to the mix, like database and caching servers or object storage. Break the app into microservices, and the number of potential failure points grows, too.
As the complexity of an application increases, so too does the risk of losing a nine in your availability metrics. While you can always throw more redundancies at the problem, you will also increase your costs and create complex engineering challenges. After all, keeping multiple copies of a database in sync is hardly a trivial problem.
With all of the information on hand about what you could do to achieve different levels of availability, the next step is to identify the consequences of losing a nine in your SLA. For example, how will your customers react if you have 54 minutes of downtime versus 540 minutes or 5,400 minutes? How many customers will you lose at each of those levels?
These are the types of questions that must be considered when crafting your SLA. High availability is important in cloud computing, but it shouldn't consume all your resources. While a five nines (99.999%) uptime may be impressive for a lawn care e-commerce giant, its customers may be far more tolerant of downtime than, say, an emergency services provider. Make sure you're not spending excessive time and energy on unnecessary redundancies.






