What is data architecture? A data management blueprint

Data architecture is a discipline that documents an organization's data assets, maps how data flows through its systems and provides a blueprint for managing data. The goal is to ensure that data is managed properly and meets business needs for information.
While data architecture can support operational applications, it most prominently defines the underlying data environment for business intelligence (BI) and advanced analytics initiatives. Its output includes a multilayer framework for data platforms and data management tools, as well as specifications and standards for collecting, integrating, transforming and storing data.
Ideally, data architecture design is the first step in the data management process. But that usually isn't the case, which creates inconsistent environments that need to be harmonized as part of a data architecture. Also, despite their foundational nature, data architectures aren't set in stone and must be updated as data and business needs change. That makes them an ongoing concern for data management teams.
Data architecture goes hand in hand with data modeling, which creates diagrams of data structures, business rules and relationships between data elements. They're separate data management disciplines, though. In an article on how data modeling and data architecture differ, David Loshin, president of consultancy Knowledge Integrity Inc., distinguished between modeling's micro focus on data assets and data architecture's broader macro perspective.
This guide to data architecture further explains what it is, why it's important and the business benefits it provides. You'll also find information on data architecture frameworks, best practices and more. Throughout the guide, there are hyperlinks to related articles that cover the topics in more depth.
How have data architectures evolved?
In the past, most data architectures were less complicated than they are now. They mostly involved structured data from transaction processing systems that was stored in relational databases. Analytics environments consisted of a data warehouse, sometimes with smaller data marts built for individual business units and an operational data store as a staging area. The transaction data was processed for analysis in batch jobs, using traditional extract, transform and load (ETL) processes for data integration.
Starting in the mid-2000s, the adoption of big data technologies in businesses added unstructured and semistructured forms of data to many architectures. That led to the deployment of data lakes, which often store raw data in its native format instead of filtering and transforming it for analysis upfront -- a big change from the data warehousing process. The new approach is driving wider use of ELT data integration, an alternative to ETL that inverts the load and transform steps.
The increased use of stream processing systems has also brought real-time data into more data architectures. Many architectures now support artificial intelligence and machine learning applications, too, in addition to the basic BI and reporting driven by data warehouses. The shift to cloud-based systems further adds to the complexity of data architectures.
Another emerging architecture concept is the data fabric, which aims to streamline data integration and management processes. It has a variety of potential use cases in data environments.
Why are data architectures important?
A well-designed data architecture is a crucial part of the data management process. It supports data integration and data quality improvement efforts, as well as data engineering and data preparation. It also enables effective data governance and the development of internal data standards. Those two things, in turn, help organizations ensure that their data is accurate and consistent.
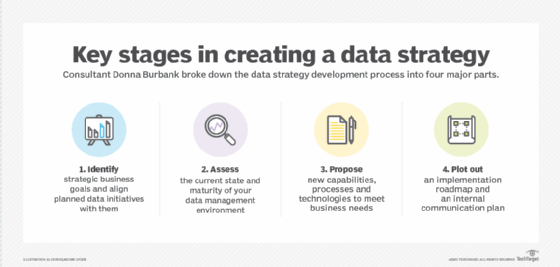
A data architecture is also the foundation of a data strategy that supports business goals and priorities. In an article on key data strategy components, Donald Farmer, principal of consultancy TreeHive Strategy, wrote that "a modern business strategy depends on data." That makes data management and analytics too important to leave to individuals, Farmer said. To manage and use data well, an organization needs to create a comprehensive data strategy, underpinned by a strong data architecture.
What are the characteristics and components of a data architecture?
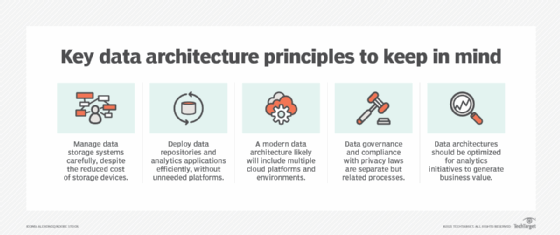
In an article on the principles of modern data architectures, Farmer stressed the importance of including both data governance and regulatory compliance processes and the growing need to support multi-cloud environments. He concluded by noting that data's potential business value will be wasted if a data architecture doesn't make it available for analytics uses.
"It's a cliché of modern data management that data is a business asset," Farmer wrote. "But data that just sits there is only a cost center, requiring maintenance without providing any business benefits."
Other common characteristics of well-designed data architectures include the following:
- a business-driven focus that's aligned with organizational strategies and data requirements;
- flexibility and scalability to enable various applications and meet new business needs for data; and
- strong security protections to prevent unauthorized data access and improper use of data.
From a purist's point of view, data architecture components don't include platforms, tools and other technologies. Instead, a data architecture is a conceptual infrastructure that's described by a set of diagrams and documents. Data management teams then use them to guide technology deployments and how data is managed.
Some examples of those components, or artifacts, are as follows:
- data models, data definitions and common vocabularies for data elements;
- data flow diagrams that illustrate how data flows through systems and applications;
- documents that map data usage to business processes, such as a CRUD matrix -- short for create, read, update and delete;
- other documents that describe business goals, concepts and functions to help align data management initiatives with them;
- policies and standards that govern how data is collected, integrated, transformed and stored; and
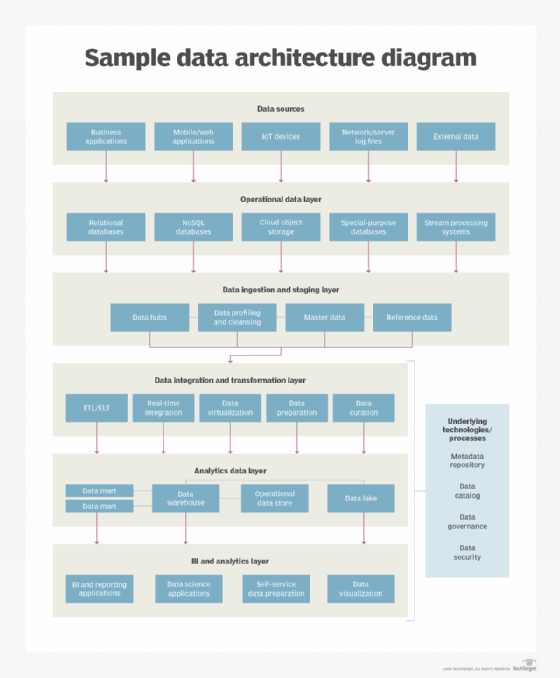
- a high-level architectural blueprint, with different layers for processes like data ingestion, data integration and data storage.
What are the benefits of a data architecture?
Ideally, a well-designed data architecture helps an organization develop effective data analytics platforms that deliver useful information and insights. In companies, those insights improve strategic planning and operational decision-making, potentially leading to better business performance and competitive advantages. They also aid in various other applications, such as the diagnosis of medical conditions and scientific research.
Data architecture also helps improve data quality, streamline data integration and reduce data storage costs, among other benefits. It does so by taking an enterprise view compared to domain-specific data modeling or focusing on architecture at the database level, according to Peter Aiken, a data management consultant and associate professor of information systems at Virginia Commonwealth University.
"When we look at it from a data architecture perspective, we have the greater value potential, and that's because we're looking at broad use [of data] across all of the databases," Aiken said during a Dataversity webinar in May 2021.
What are the risks of bad data architecture design?
One data architecture pitfall is too much complexity. The dreaded "spaghetti architecture" is evidence of that, with a tangle of lines representing different data flows and point-to-point connections. The result is a ramshackle data environment with incompatible data silos that are hard to integrate for analytics uses. Ironically, data architecture projects often aim to bring order to existing messy environments that developed organically. But if not managed carefully, they can create similar problems.
Another challenge is getting universal agreement on standardized data definitions, formats and requirements. Without that, it's hard to create an effective data architecture. The same goes for putting data in a business context. Done well, data architecture "captures the business meaning of the data required to run the organization," Aiken said in the Dataversity webinar. But failing to do so may create a disconnect between the architecture and the strategic data requirements it's supposed to meet.
Data architecture vs. data modeling
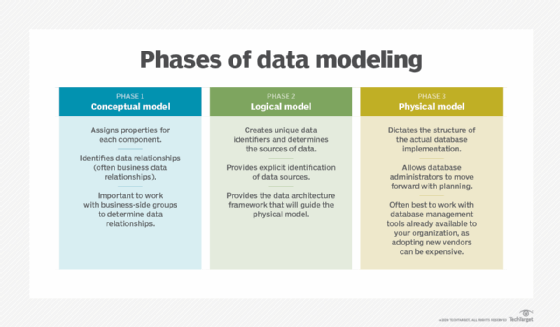
Data modeling focuses on the details of specific data assets. It creates a visual representation of data entities, their attributes and how different entities relate to each other. That helps in scoping the data requirements for applications and systems and then designing database structures for the data, a process that's done through a progression of conceptual, logical and physical data models.
Data architecture takes a more global view of an organization's data to create a framework for data management and usage. But, as consultant Loshin wrote in his article comparing the two, data modeling and data architecture complement each other. Data models are a crucial element in data architectures, and an established data architecture simplifies data modeling, said Loshin, who also is director of the Master of Information Management program at the University of Maryland's College of Information Studies.
Rick Sherman, managing partner at consulting firm Athena IT Solutions, separately explained seven techniques for modeling data, including the entity-relationship, dimensional and graph modeling approaches that are most used now. He also outlined a set of data modeling best practices, including these recommendations:
- Gather both business and data requirements upfront, before building models.
- Develop data models iteratively and incrementally to make the process manageable.
- Use data models as a tool for communicating with business users about their needs.
- Manage data models just like any other type of application code.
Data architecture vs. information architecture and enterprise architecture
In a second article, Sherman described the difference between data architecture and information architecture in enterprise applications. "Information is data in context," he wrote. "An information architecture defines the context that an enterprise uses for its business operations and management." A data architecture that delivers high-quality, reliable data is the foundation for the information architecture, he added.
Meanwhile, data architecture is commonly viewed as a subset of enterprise architecture (EA), which aims to create an organizational blueprint for an organization in four domains. EA also encompasses the following:
- business architecture, which involves business strategy and key business processes;
- application architecture, which focuses on individual applications and their relationships to business processes; and
- technology architecture, which includes IT systems, networks and other technologies that support the other three domains.
What data architecture frameworks are available?
Organizations can use standardized frameworks to design and implement data architectures instead of starting completely from scratch. These are three well-known framework options:
DAMA-DMBOK2. The DAMA Guide to the Data Management Body of Knowledge is a data management framework and reference guide created by DAMA International, a professional association for data managers. Now in its second edition and commonly known as DAMA-DMBOK2, the framework addresses data architecture along with other data management disciplines. The first edition was published in 2009, and the second one became available in 2017.
TOGAF. Created in 1995 and updated several times since then, TOGAF is an enterprise architecture framework and methodology that includes a section on data architecture design and roadmap development. It was developed by The Open Group, and TOGAF initially stood for The Open Group Architecture Framework. But it's now referred to simply as the TOGAF standard.
The Zachman Framework. This is an ontology framework that uses a 6-x-6 matrix of rows and columns to describe an enterprise architecture, including data elements. It doesn't include an implementation methodology; instead, it's meant to serve as the basis for an architecture. The framework was originally developed in 1987 by John Zachman, an IBM executive who retired from the company in 1990 and founded a consulting firm called Zachman International.
Key steps for creating a data architecture
Data management teams must work closely with business executives and other end users to develop a data architecture. If they don't, it may not be in tune with business strategies and data requirements. Engaging with senior execs to get their support and meeting with users to understand their data needs are two of the nine data architecture planning steps that consultant Loshin listed in an article.
Among other steps, he also recommended that organizations do the following:
- evaluate data risks based on data governance directives;
- track data flows, as well as data lifecycle and data lineage info;
- document and appraise the existing data management technology infrastructure; and
- scope out a roadmap for the data architecture deployment projects.
Another article, by technology writer George Lawton, provides tips on building a cloud-based architecture for data management and analytics. It also outlines potential challenges that data management teams can face in the cloud, including data security requirements, regulatory compliance mandates and data gravity issues that can complicate migrations of data sets.
Read more about data architecture:
Top data architect and data engineer certifications
Data architect skills required, responsibilities and salaries
What are the different roles in data architecture design and development?
The lead role in data architecture initiatives typically goes to data architects. They need a variety of technical skills, as well as the ability to interact and communicate with business users. A data architect spends a lot of time working with end users to document business processes and existing data usage, as well as new data requirements.
On the technical side, data architects create data models themselves and supervise modeling work by others. They also build data architecture blueprints, data flow diagrams and other artifacts. Other duties may involve outlining data integration processes and overseeing the development of data definitions, business glossaries and data catalogs. In some organizations, data architects also are responsible for designing data platforms and evaluating and selecting technologies.
Other data management professionals who often are involved in the data architecture process include the following:
- Data modelers. They also work with business users to assess data needs and review business processes. Then, they use the information they've gathered to create data models.
- Data integration developers. Once the architecture is implemented, they're tasked with creating ETL and ELT jobs to integrate data sets.
- Data engineers. They build pipelines to funnel data to data scientists and other analysts. They also help data science teams with the data preparation process.





