root cause analysis

What is root cause analysis?
Root cause analysis (RCA) is a method for understanding the underlying cause of an observed or experienced incident. An RCA examines the incident's causal factors, focusing on why, how and when they occurred. An organization will often initiate an RCA to get at the principal source of a problem to ensure it doesn't happen again.
When a system breaks or changes, investigators should perform an RCA to fully understand the incident and what brought it about. Root cause analysis is a step beyond problem-solving, which is corrective action taken when the incident occurs. In contrast, an RCA gets at a problem's root cause.
In some cases, an RCA is used to better understand why a system is operating in a certain way or is outperforming comparable systems. For the most part, however, the focus is on problems -- especially when they affect critical systems. An RCA identifies all factors that contribute to the problem, connecting events in a meaningful way so that the issue can be properly addressed and prevented from reoccurring. Only by getting to the root of the problem, rather than focusing on the symptoms, is it possible to identify how, when and why the problem occurred.
Problems that warrant an RCA can be the result of human error, malfunctioning physical systems, issues with an organization's processes or operations, or any number of other reasons. For example, investigators might launch an RCA when machinery fails in a manufacturing plant, an airplane makes an emergency landing or a web application experiences a service disruption. Any type of anomaly can potentially necessitate an RCA.
This article is part of
What is APM? Application performance monitoring guide
Goals and benefits of root cause analysis
The main purpose of root cause analysis is to reduce risk to the overall organization. The information discovered in this process can be used to enhance a system's reliability. The main goals of an RCA are threefold:
- Identify exactly what has been occurring, going beyond just the symptoms to get to the actual sequence of events and primary causes.
- Understand what it will take to address the incident or to apply what has been learned from that incident, while taking into account its causal factors.
- Apply what has been learned to prevent the problem from reoccurring or to duplicate the underlying conditions.
When an RCA achieves these goals, it can offer an organization the following benefits:
- Optimize systems, processes or operations by providing insights into underlying issues and roadblocks.
- Prevent the same or similar issues from reoccurring and lead to higher-quality management.
- Deliver higher-quality customer and client services by addressing issues more efficiently and thoroughly.
- Lead to better in-house communication and collaboration, along with an improved knowledge of the underlying systems.
- Reduce the time spent over the long term trying to resolve issues, rather than repeatedly focusing on the symptoms.
- Lower costs by getting to the root of the problem sooner, rather than continuously treating the symptoms.
Root cause analysis can benefit a wide range of industries. When used effectively, it can help improve medical treatments, reduce on-the-job injuries, deliver better application performance, optimize infrastructure uptime, minimize machinery maintenance, provide safer transportation, and benefit a variety of other systems and processes.
Root cause analysis principles
Root cause analysis is flexible enough to accommodate different types of industries and individual circumstances. Yet beneath this flexibility, the following four important principles are essential to making RCA work:
1. Learn why, how and when the incident occurred
These questions work together to provide a complete picture of the underlying causes. For example, it can be difficult to know why an event occurred if you don't know how or when it happened. Investigators must uncover an incident's full magnitude and all the key ingredients that went into making it happen at the time it happened.
2. Focus on the underlying causes, not the symptoms
Addressing only the symptoms when a problem arises rarely prevents that problem from reoccurring, and can waste both time and resources. An RCA effort should instead focus on the relationships between events and the incident's underlying root causes. In the end, this can help reduce the time and resources spent on resolving issues and ensure a viable solution over the long term.
3. Think prevention when using RCA to solve problems
To be effective, an RCA effort must get to a problem's root causes -- but that's not enough. It must also make it possible to implement solutions that prevent the problem from reoccurring. If the RCA doesn't help fix the problem and keep it from happening again, much of the effort will have been wasted.
4. Do it right the first time
An RCA is only as successful as the effort behind it. A poorly executed RCA can waste time and resources. It might even make the situation worse, forcing investigators to start over. An effective root cause analysis must be carried out carefully and systematically. It requires the right methods and tools, as well as leadership that understands what the effort involves and fully supports it.
Root cause analysis methods
One of the most popular methods used for root cause analysis is the 5 Whys. This approach defines the problem and then keeps asking "why" questions to each answer. The idea is to keep digging until you uncover reasons that explain the "why" of what happened. The number five in the methodology's name is just a guide, as it might take fewer or more "why" questions to get to the root causes of the originally defined problem.
Another popular approach to RCA is to create a cause-and-effect Ishikawa diagram, or fishbone diagram, where the problem is defined in the head of the fishbone shape, and its causes and effects are splayed out behind it. Possible causes are grouped into categories that connect to the spine, providing an overall view of the causes that might have led to the incident.
The following methodologies are also available to investigators when conducting a root cause analysis:
- Failure mode and effects analysis (FMEA). FMEA identifies different ways in which a system can potentially fail and then analyzes the possible effects of each failure.
- Fault tree analysis (FTA). FTA provides a visual mapping of causal relationships that uses Boolean logic to determine a failure's potential causes or to test a system's reliability.
- Pareto chart. This is a combination bar chart and line chart that maps out the frequency of the most common root causes of problems, listed from left to right, starting with the most probable.
- Change analysis. This type of analysis considers how conditions surrounding the incident have changed over time, which can play a direct role in bringing about the incident.
- Scatter chart. This type of diagram plots data on a two-dimensional chart with an x-axis and y-axis to uncover relationships in the data as they pertain to an incident's potential causes.
There are also several other approaches that are used for RCA. Professionals who focus on root cause analysis and are seeking continuous improvement in reliability should understand multiple methods and use the appropriate one for a given scenario.
Successful root cause analysis also depends on good communication within the group and staff involved in a system. Debriefing after an RCA -- often called a post-mortem -- helps to ensure the key players understand the time frames of casual or related factors, their effects, and the resolution methods used. Post-mortem information sharing can also lead to brainstorming around other areas that might need to be investigated and who should look into what areas.
Tools for root cause analysis
Root cause analysis is a process that pairs human deduction with data gathering and reporting tools. IT teams often turn to the platforms they're already using for application performance monitoring, infrastructure performance monitoring or systems management -- including cloud management tools -- for the background data they need to carry out the RCA.
Many of these products also include features built into their platforms to help with root cause analysis. In addition, some vendors offer tools that collect and correlate the metrics from other platforms to help remediate a problem or outage event. Tools that include AIOps capabilities are able to learn from prior events to suggest remediation actions in the future.
In addition to monitoring and analysis tools, IT organizations often rely on external sources to help with their root cause analysis. For example, IT team members might check the AWS Health Dashboard to learn about service issues, or they might participate in Stack Overflow discussions to get others' expertise on topics related to their RCA.
Root cause analysis examples
Root cause analysis is used by a wide range of industries and in a variety of situations, making it a highly valuable tool that's flexible enough to accommodate specific circumstances. The following are examples of RCA in action, but the possibilities for its use are nearly limitless.
Example 1: Disruption in email service. Users couldn't send or receive email messages for two hours, and the boss wants to know what happened. The IT team is tasked with carrying out a root cause analysis.
The team begins by defining a problem statement and collecting relevant data. Next, they use the 5 Whys method to uncover the contributing events and underlying cause as follows:
- Why did emails stop working? Because mail flow stopped.
- Why did mail flow stop? Because someone installed patches during the day.
- Why was the patch deployed during the day? Because the admin did not follow the rules in IT's processes to patch after business hours.
- Why did this cause a two-hour outage? Because a patch disabled a service, and it took that long during the chaos to troubleshoot and resolve the outage.
The answers to the "why" questions give an outline of what happened and what went wrong. From this information, the IT team can take action to improve patching procedures and prevent this same situation from happening in the future.
Example 2: Drop in mobile app active users. The number of active users of a popular mobile app has steadily dropped over the past two weeks, and several teams within the organization are scrambling to make sense of what happened. Individuals from each of these teams are working together to conduct an RCA.
After gathering the necessary data, the RCA team generates a fishbone diagram to better understand possible causes and their effects. The team members come up with the following diagram.
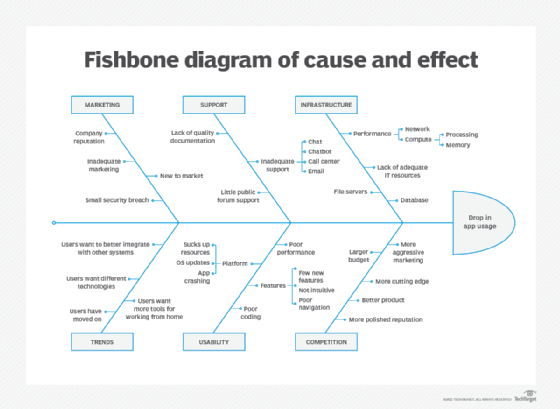
The diagram helps them identify all the potential root causes, and from this, they can drill into each one to determine its viability. For example, they can use data generated by their monitoring software to verify whether there have been any issues with infrastructure performance or the back-end systems.
After analyzing each potential root cause, the RCA team determines that the most likely cause was the recent release of a similar app by a top competitor. The app was well marketed, included cutting-edge technology and integrated with several third-party services.
From this information, the team develops a strategy for accelerating the next update of their own application to provide a competitive edge over the other app. They also communicate this information with the marketing and customer support teams so that they're prepared for the next release.
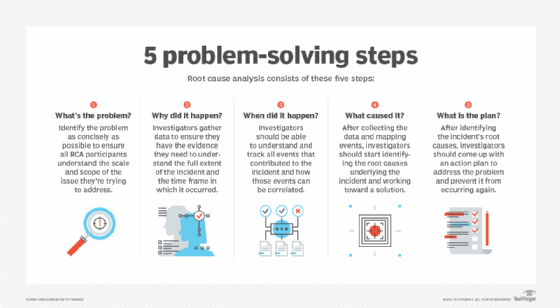
How to conduct a root cause analysis
Conducting a root cause analysis can be a complex undertaking that requires both time and resources. A team that's carrying out an RCA should take a systematic approach that's built on open communication and careful planning. Although there's no single approach to RCA, a team should consider starting with the following five basic steps:
1. Define the problem. It might seem obvious, but the first step should be to identify the problem as concisely as possible to ensure all RCA participants understand the scale and scope of the issue they're trying to address.
- Create a clearly defined problem statement.
- Identify the specific symptoms surrounding the problem.
- Document the effects of the problem on the target system, as well as peripheral and supporting systems.
- Ensure all key players understand and agree on the nature of the problem.
- If there are multiple problems, deal with them one at a time.
2. Collect all relevant data. Investigators require whatever data is necessary to ensure they have the evidence they need to understand the full extent of the incident and the time frame in which it occurred.
- Data gathering should be a methodical process that's carefully documented and verified.
- Investigators need access to all relevant evidence related to the incident, without exception.
- The data should include any information specific to the incident itself and any suspected causes.
- The collected data should cover the entire applicable time frame, which can include data from before and after the incident.
- The data should include details about any special circumstances or environmental factors that might have contributed to the incident.
3. Identify and map events. Investigators should be able to understand and track all events that contributed to the incident and how those events can be correlated.
- The RCA team should identify the sequence of events and the timeline in which they occurred.
- The team should also determine the conditions under which the events occurred.
- Events should be correlated to determine what links might exist between them.
- The collected data should be examined for any causal factors that contributed to the events or that are somehow related to the events.
- Any other factors that could have potentially contributed to the incident should be examined.
4. Identify the root cause. After collecting the data and mapping events, investigators should start identifying the root causes underlying the incident and working toward a solution.
- Investigators need to analyze all contributing factors and relevant data.
- From their analysis, investigators should identify any potential root causes that seem feasible within the given circumstances.
- Investigators should carefully analyze each potential root cause, eliminating those least viable and digging deeper into those most likely to have contributed to the incident.
- Multiple causes might have contributed to the incident, and they all need to be identified and analyzed.
- After identifying the real root causes, investigators should try to confirm their validity by simulating the circumstances that led to the incident, when and where this is practical.
5. Implement a solution. After identifying the incident's root causes, investigators should come up with an action plan for how to address the root problem and prevent it from occurring in the future.
- The solution should map back to the problem statement created in the first step.
- Investigators should carefully outline what needs to be done and what it will take to get it done, including the potential effects on individuals or operating environments.
- The RCA team, with the help of other individuals, should provide a strategy for how to implement the solution, taking into account such factors as timelines, budgets and specific roles.
- Investigators should identify any potential roadblocks to implementing the solution.
- After the solution has been deployed, the RCA team should carefully monitor and evaluate its implementation to ensure the solution has effectively addressed the underlying issues.
When carrying out an RCA, investigators should use the methods and tools most appropriate for their particular situation. They should also put into place a system for verifying each stage of the RCA effort to ensure every step is done correctly. As part of this process, investigators should carefully document each phase, starting with the problem statement and continuing through to the solution's implementation.
In order for the root cause analysis process to be effective, an organization needs to coordinate its RCA activities among its various teams. Learn which three approaches work best for team coordination.







