
serverless computing

What is serverless computing?
Serverless computing is a cloud computing execution model that lets software developers build and run applications and servers without having to provision or manage the back-end infrastructure. With serverless, the cloud vendor takes care of all routine infrastructure management and maintenance, including updating the operating system (OS), applying patches, managing security, system monitoring and planning capacity.
With serverless computing, developers purchase back-end services from cloud services vendors on a pay-as-you-go basis, which means they pay only for the services used. The main goal of serverless computing is to make it simpler for developers to write code designed to run on cloud platforms and to perform a specific role.
How serverless computing works
With serverless computing, developers don't have to deal with managing machine instances in the cloud. Instead, they can run code on cloud servers without having to configure or maintain the servers. Pricing is based on the actual amount of resources consumed by an application rather than on pre-purchased units of capacity.
Typically, if developers host their applications on virtual servers based in the cloud, they must set up and manage those servers, install OSes on them, monitor them and continually update the software.
With a serverless model, developers can write a function in their favorite programming language and post it to a serverless platform. The cloud service provider manages the infrastructure and the software, and maps the function to an application programming interface (API) endpoint, transparently scaling function instances on demand.
Advantages and disadvantages of serverless computing
The advantages of serverless computing include the following:
- Cost-effectiveness. Users and developers pay only for the time when code runs on a serverless compute platform. They don't pay for idle virtual machines (VMs).
- Easy deployment. Developers can deploy apps in hours or days rather than weeks or months.
- Autoscaling. Cloud providers handle scaling up or spinning down resources or instances when the code isn't running.
- Increased developer productivity. Developers can spend most of their time writing and developing apps instead of dealing with servers and runtimes.
The disadvantages of serverless computing include the following:
- Vendor lock-in. Switching cloud providers might be difficult because the way serverless services are delivered can vary from one vendor to another.
- Inefficient for long-running apps. Sometimes using long-running tasks can cost much more than running a workload on a VM or dedicated server.
- Latency. There's a delay in the time it takes for a scalable serverless platform to handle a function for the first time, often known as a cold start.
- Debugging is more difficult. Because a serverless instance creates a new version of itself each time it spins up, it's hard to amass the data needed to debug and fix a serverless function.
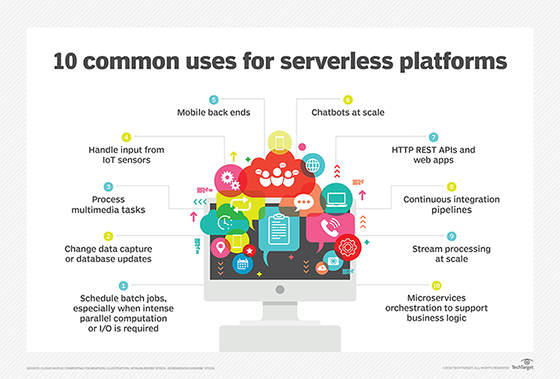
Serverless computing use cases
There are numerous use cases for serverless computing:
- Event-triggered computing. For scenarios that involve numerous devices accessing various file types, such as mobile phones and PCs uploading videos, text files and images.
- Internet of things (IoT) data processing. Serverless computing provides a way to combine and analyze data from a variety of devices and then trigger the desired events, offering a highly functional, less expensive way to manage IoT.
- Back-end tasks for mobile apps or websites. A serverless function can take a request -- such as for information from a user database -- from the front end of the site or application, retrieve the information and hand it back to the front end.
- High-volume background processes. Serverless can be used to transfer data to long-term storage; convert, process and analyze the data; and move metrics to an analytics service.
- Microservices support. Supporting microservices architectures is one of the most common uses of serverless computing. Although developers can use containers or platform as a service (PaaS) to build and operate microservices, they can also use serverless computing because of its inherent and automatic scaling, rapid provisioning, attributes around small bits of code, and pricing model that only charges for the capacity used.
- Building RESTful APIs. Serverless computing makes it easier to build RESTful APIs developers can scale up on demand.
- Video and image manipulation. Serverless computing enables developers to modify video transcoding for different devices and to resize images dynamically.
- Writing multilanguage apps. When developers create applications, one of the first factors to consider is what language to use. Since serverless is a polyglot environment, developers can write code in any language or framework they choose, including Python, Node.js, Java and JavaScript.
- Continuous integration/continuous delivery (CI/CD). CI/CD pipelines let developers ship small bits of code, which means they can ship bug fixes and other updates every day. Serverless architectures can automate many of the workflows in developers' CI/CD pipelines -- for example, pull requests triggering automated tests.
Serverless vs. other cloud back-end models
There are numerous differences between serverless computing and other cloud back-end models, such as infrastructure as a service (IaaS), backend as a service (BaaS) and PaaS.
Serverless vs. IaaS
Under the IaaS cloud computing model, developers pre-purchase units of capacity rather than on demand as with serverless computing. This means organizations pay public cloud vendors for server components that are always on to run the main components of their applications.
Consequently, an organization's server administrator and tech team are responsible for estimating how much capacity the company uses on average per month to select a pricing plan that meets its needs.
However, serverless architecture applications are deployed only when necessary, as an event triggers the application code to run. The public cloud vendor allocates the resources needed for that operation to run, and the company stops paying when the code finishes running.
Serverless vs. BaaS
One of the primary differences between BaaS and serverless computing is scalability. With serverless, the scale of the application automatically increases depending on app use. The cloud provider's infrastructure automatically assigns the servers or containers needed to initiate this increase.
BaaS might not automatically scale an application because some BaaS platforms have a request-per-second limitation to prevent automated scaling. However, many BaaS vendors offer platforms that work much like serverless computing and scale apps automatically.
In addition, since serverless architectures are event-driven, they run in response to events. But BaaS apps are typically not event-driven, which means they need more server resources.
Serverless vs. PaaS
Scaling up and down is easy with serverless apps because it depends on demand and doesn't require developer intervention.
While a PaaS offering also enables scalability, developers are required to set up the scaling parameters. In general, PaaS provides developers better control over their deployment environments than serverless computing.
With serverless, developers only pay for what they use. With PaaS, developers typically pay a monthly fee for services -- no matter how much they use -- which is much more predictable and might end up being less expensive.
For more on public cloud, read the following articles:
8 key characteristics of cloud computing
The pros and cons of cloud computing explained
Role of serverless computing in digital transformation
Serverless computing plays an important part in digital transformation. First, it enables developers to be more productive by helping them focus on writing code that has business value, without having to worry about the underlying infrastructure that will support the code. Regardless of vertical industry or company size, a serverless computing strategy can help increase developer productivity by eliminating management overhead.
Features of a serverless computing software development environment include the following:
- zero server management;
- autoscaling to meet changing traffic demands; and
- managed integrated security.
What to look for in a serverless architecture
Organizations should look for serverless platforms that help them develop applications end to end, tapping services across databases, storage, messaging, data analytics, machine learning and smart assistants.
Some serverless cloud services provide scalability and cost savings, but they can create additional complexities -- such as constrained runtimes or vendor lock-in -- so that's also an important consideration when choosing a serverless architecture.
Developers often face a hard tradeoff between the ease and velocity of serverless computing and the flexibility and portability of containers. This is why most organizations benefit from a full-stack approach rather than limiting serverless to compute functions.
Serverless computing vendors and languages
The major serverless computing vendors include the following:
- Google Cloud Functions. Released by Google in 2017, it supports Node.js, JavaScript, Python and Go, but allows for unlimited execution time for functions. Google Cloud Functions can also interact with many other Google services, enabling developers to quickly create and manage complex enterprise-class applications with almost no consideration of the underlying servers.
- IBM Cloud Functions. Based on Apache OpenWhisk, it supports JavaScript (Node.js), Swift and Cloudflare Workers, which runs functions written in JavaScript and any language that can be compiled to WebAssembly.
- Amazon Web Services (AWS) Lambda. Introduced in 2014, it's a function as a service (FaaS) offering from AWS. AWS Lambda functions can be written in Java, Go, PowerShell, Node.js, JavaScript, C#, Python and Ruby.
- Microsoft Azure Functions. Microsoft rolled out Azure Functions in 2016 to compete with AWS Lambda. It supports Bash, Batch, C#, F#, Java, JavaScript (Node.js), PHP, PowerShell, Python and TypeScript.
- Cloudflare Workers. Released in 2018, Cloudflare Workers combines edge computing with the FaaS model. It supports JavaScript and WebAssembly-compatible languages.
- Netlify Functions. Rolled out in 2018, Netlify Functions, which is built on top of AWS Lambda, lets developers deploy server-side code as API endpoints. Developers can write functions in JavaScript, TypeScript and Go.
- Vercel Serverless Functions. Vercel Serverless Functions aims to simplify the serverless experience for web app developers. It supports Node.js, Go, Python and Ruby.
- Oracle Functions. Released in 2019, Oracle Functions integrates with Oracle Cloud Infrastructure, platform services and SaaS applications. Oracle Functions is based on the open source Fn Project. It supports Java, Python, Node.js, Go, Ruby and C#; for advanced use cases, developers can bring their own Dockerfiles and GraalVM.
Development tools
There are numerous third-party vendor tools developers can use when they're working with serverless computing, including the following:
- LambCI. A package that can be uploaded to AWS Lambda to bring CI to serverless.
- Dashbird. A monitoring, debugging and intelligence platform to help developers build, operate, improve and scale apps on AWS.
- Sls-dev-tools. A set of open source tools that make it easy for developers to interact with their serverless functions.
- Serverless-iam-roles-per-function. An open source tool that lets developers easily and quickly define access roles for different serverless functions.
- Thundra. A platform that enables developers to monitor, debug and test their serverless applications.
Future of serverless computing
The global serverless computing market is expected to increase by more than 23.17% between 2021 and 2026, according to a report from Mordor Intelligence.
"Advancements in computing technology are enabling organizations to incorporate a serverless environment, thereby augmenting the market," the report said. "The benefits of Serverless Computing such as unconditional development and deployment, built-in scalability among others are playing an important role in supporting the rapid adoption of Serverless Computing thereby fueling the growth of the market."







