configuration management database (CMDB)
What is a configuration management database (CMDB)?
A configuration management database (CMDB) is a file -- usually in the form of a standardized database -- that contains all relevant information about the hardware and software components used in an organization's IT services and the relationships among those components. A CMDB stores information that provides an organized view of configuration data and a means of examining that data from any desired perspective.
As IT infrastructure becomes more complex, the importance of tracking and understanding the information within the IT environment increases. The use of CMDBs is a best practice for IT teams and leaders who need to identify and verify each component of their infrastructure to better manage and improve it.
How CMDBs work and why they are important
Within the context of a CMDB, components of an information system are referred to as configuration items (CIs). CIs can be any conceivable IT components, including software, hardware, documentation and personnel. They can also indicate the way in which each CI is configured and any relationship or dependencies among them. The processes of configuration management seek to specify, control and track CIs and any changes made to them in a comprehensive and systematic fashion.
CMDBs capture attributes of the CIs, including CI importance, CI ownership and CI identification code. A CMDB also provides details about the relationships and dependencies between CIs, which is a powerful tool if used correctly. As a business enters more CIs into the system, the CMDB becomes a stronger resource to predict changes within the organization. For example, if an outage occurs, IT can understand from the CI data which systems are affected.
This article is part of
What is configuration management? A comprehensive guide
A CMDB can be used for many activities in addition to capturing CI data, including the following:
- Performing problem management.
- Conducting root cause analysis.
- Identifying potential vulnerabilities.
- Complying with regulatory metrics.
- Investigating workflows.
- Reducing downtime.
- Enhancing service delivery.
- Providing optimization of business services.
- Tracking software licenses.
- Capturing real-time data on potential performance issues.
The CMDB connects to virtually every element in the IT infrastructure. It provides asset management, as well as configuration data for system and network administration and security management. Data from the CMDB is typically presented on a dashboard display.
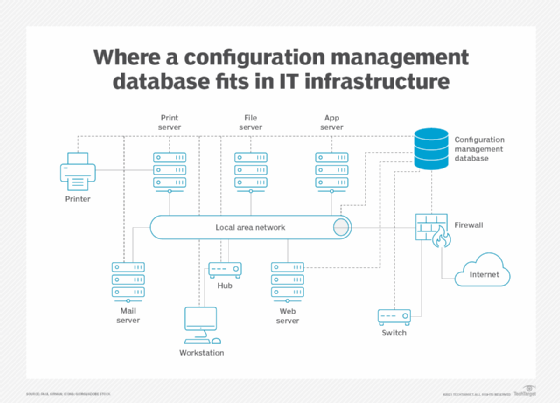
Who needs CMDBs?
IT organizations need CMDBs to capture information about the CIs. CMDBs can be paired with asset management systems to identify all elements within an IT infrastructure. CMDBs build on asset inventories, providing information on the relationships among CIs.
Organizations use the CMDB to predict changes that can affect IT systems, which systems will be affected and how. IT administrators can also use CMDB data to identify when it's appropriate or necessary to replace a device or other asset.
Advantages of a CMDB
CMDBs provide various benefits, including the following:
- Centralized view of data. This capability gives IT administrators more control over the IT infrastructure. Admins can get data on each component in an IT infrastructure -- for example, a storage device or an application running on a server. This helps with planning, managing and maintaining the entire infrastructure. It also prevents administrative and management errors, helps to ensure regulatory compliance and increases security.
- Cost savings. CMDBs enable IT managers to spot ways to eliminate unnecessary or redundant IT resources and their associated costs.
- Data integration. CMDBs let admins integrate data from various vendors' software, reconcile that data, identify any inconsistencies within the database and then ensure all data is synchronized. A CMDB system can also integrate other configuration-related processes, such as change management and incident management, to better manage the IT environment.
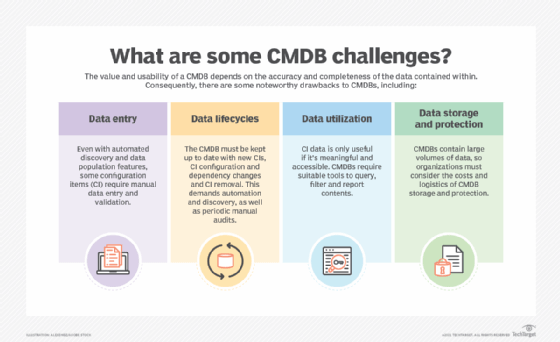
Challenges of a CMDB
A CMDB can also present a number of challenges. A particularly difficult issue is organizational in nature: to convince the business of the benefits of a CMDB and then to use the system properly once it is implemented.
Once implemented, other challenges include the following:
- Importing relevant data. This can be a tedious task because admins must input a wealth of information about each IT asset, including financial information, upgrade history and performance profile. Modern CMDB tools offer enhanced discovery capabilities, enabling the tool to find and profile CIs automatically. However, this data doesn't always come from the same source. In theory, a process called data federation brings together data from disparate locations to prevent IT from replacing or eliminating other data systems. In practice, data is dispersed across sources that aren't well integrated, which prevents IT managers from federating data.
- Updating and maintaining CMDBs. Over time, IT administrators must regularly review, update and maintain CMDB data. A CMDB can fail if admins don't update the data, and it becomes stale and unusable.
Evolution of the CMDB
A CMDB is a single source of truth of configuration information for IT assets, so it can be easily managed to deliver services. Visibility and monitoring of assets and dependencies streamlines upgrades and the deployment of new services. For example, CMDB data can help identify which servers run an older operating system (OS) version and how patches might alter security and performance.
Organizations can track and enforce CMDB information over time, which improves security and compliance and reduces risks. CMDBs also play a central role in automated failover and disaster recovery activities.
Recently, the term configuration management has expanded its meaning to reflect the increased use of software-based configurations and interactions: scripting the configuration of a software stack, container management and Kubernetes, automation down to the code level, and cloud resources and provisioning.
The DevOps universe of technologies and practices, including containers, microservices, infrastructure as code, source control, package management and release automation, has changed what it means to map and track asset configurations and dependencies. Machine learning and artificial intelligence promise to predict the impact of undesirable results more quickly and accurately from configuration changes and their propagation.

The role of configuration management for tracking configuration changes in physical and digital assets hasn't gone away. Organizations still need to understand the landscape of their IT infrastructure resources and how the interplay of those resources supports business objectives.
CMDBs have evolved to more closely align with IT service management (ITSM) and reporting capabilities, as well as the cloud and distributed infrastructure. Many CMDBs integrate with IT asset management (ITAM) platforms, which are similar information repositories about IT assets that support change management. CMDBs can also be used to store such information themselves.
CMDBs and ITIL
The IT Infrastructure Library service management framework includes specifications for configuration management, although adoption of the ITIL framework isn't a prerequisite for configuration management. According to ITIL specifications, the four major aspects of configuration management are the following:
- Discovery. Identify CIs to be included in the CMDB.
- Security. Control data to ensure that it can only be changed by authorized individuals.
- Reporting. Maintain status, ensuring that the status of any CI is consistently recorded and updated.
- Auditing. Verify through audits and reviews of the data to ensure that it's accurate.
ITIL v2 (2000) introduced the concept of configuration management, which captures details of all configuration items as part of ITSM activities. ITIL v3 (2007) expanded this approach into a formal configuration management system, composed of CMDBs acting in concert, providing an important resource for service management and other management activities. ITIL v4 (2019) provided an IT operations model for delivering products and services. It plays a role in the overall business strategy.
CMDBs vs. asset management
There is functional overlap between CMDBs and ITAM platforms for change management. Their capabilities are also increasingly integrated into broader service management frameworks. However, they are different tools used for different purposes.
ITAM tools track asset data, such as hardware and software details, across the entire asset lifecycle. That data tends to be more static than the dynamic activities a CMDB tracks: acquisition and procurement, operation, change management, maintenance and disposal.
ITAM data includes configuration information. It also tracks costs at each lifecycle stage, such as purchasing and licensing, service, support and depreciation. Asset management benefits include better asset utilization and proactive asset compliance and security auditing. Improved asset visibility also leads to faster and more accurate business decision-making.
ITAM tools typically are used to achieve business-oriented goals, such as making and reviewing decisions through an infrastructure asset lifecycle. Configuration management tools are better served for service-oriented goals, helping IT staff understand dependencies so they can plan and maintain IT services. Change management is an important activity CMDBs support.
ITAM and a CMDB aren't mutually exclusive. For example, an application server is an IT asset with financial value that depreciates over time. It also requires maintenance and can incorporate operational information, such as service agreements, that aren't part of a CMDB. That server also is a CI, and information about it can be tracked and managed through a CMDB, including its installed OS and software, server setup and firmware versions. The CMDB could reveal how changes to the server's configuration state might affect performance, stability and security; this is called an impact analysis.
CMDB vendors and tools
General capabilities of a CMDB include the following:
- Discover and assess the CI of IT assets.
- Automatically update CMDB entries when an asset is changed or updated.
- Map dependencies between assets and CIs.
- Simulate or predict the effect of a change to CIs.
- Audit CMDB records for security and compliance initiatives.
Many configuration management and CMDB tools are available for enterprises of various sizes and needs. The following are some examples of such apps:
- AlgoSec.
- BMC Helix CMDB.
- Broadcom CA Service Management.
- Canfigure.
- Freshservice.
- GLPI.
- IBM Control Desk.
- IBM Tivoli Change and Configuration Management Database.
- ManageEngine AssetExplorer.
- Microsoft System Center Service Manager.
- OpenText Universal Discovery and Universal CMDB.
- ServiceNow CMDB.
- Snow ITSM Enhancer.
- SolarWinds Service Desk.
- Virima.
Integrated and third-party tools are also available to supplement a CMDB, such as the following:
- ITSM tools can integrate with CMDBs and often incorporate CMDB capabilities of their own. Many ITSM vendors offer standalone CMDBs as well. Tools from a single vendor may offer integration advantages but less so for users of third-party CMDBs.
- Automated discovery and change management tools automatically generate and update data to capture the state of the IT environment. However, while discovery tools enable IT to take a more hands-off approach to configuration management, they don't eliminate the need for manual entry. For example, admins may need to manually enter some details, such as the hardware's purchase date, price and due date of the next renewal of service.
- IT operations analytics tools can integrate with CMDBs. These tools can analyze the established configuration of each server, compare possible changes against an existing benchmark and alert IT managers to unexpected or disallowed changes to a configuration for examination and remediation.
- Data management tools can address data federation by taking all IT data from a variety of sources and automatically storing it in a CMDB. Such tools increase the accuracy of an enterprise's CMDB data.
- Unified endpoint management and software asset management tools are used as data sources for a CMDB to provide visibility for devices within their control.
Find out more about the relationship between change management and configuration management.






