Inside businesses of all shapes and sizes, modern IT teams have adopted DevOps practices to roll out changes faster, while delivering more stable software on more reliable infrastructure. Anyone can do it, as long as they learn fundamental skills.
IT teams must embrace infrastructure as code (IaC) to apply DevOps practices. IaC enables automation, testability, quality control and more predictability during deployments. Perhaps more importantly, it demands that infrastructure-focused team members become aware of software development practices.
A DevOps version control process enables IT professionals to define IaC, store infrastructure templates and other artifacts, and update configurations frequently without sacrificing consistency. With version control for infrastructure code, everyone on the DevOps team gets a clear picture of all the IT resources required to support an application, along with a complete point-in-time history from one revision to the next
The DevOps version control process
The concept of a version control repository is simple: Code versions are organized so users can track change over time. Changes and updates are incrementally stacked on top of the previous information to create a new version of the code, but you can roll back to an older deployment easily at any given time.
The version control workflow reduces the risk of multiple versions of an application spreading across multiple development machines or servers. Bugs and updates that break are reverted until the code works as expected.
The version control process is standard fare for software development teams. When infrastructure-focused team members understand how to apply DevOps version control basics to their own assets, it breaks down barriers and gives everyone a common starting point. Every change, whether it's to application code or infrastructure code, occurs within the confines of the version control repository. Those updates also include a description of what was changed since the previous version. For example, a bug was fixed, or a software patch was applied to an OS image referenced by an infrastructure template.
The version control process reduces conflicts when working within teams. Each team member can synchronize a copy of the code from a central repository and merge changes back in when ready. Multiple team members work on the same code base at any given time, improving productivity and collaboration.
The version control process reduces conflicts when working within teams.
Perhaps one of the most important aspects of DevOps version control is task automation. DevOps engineers build triggers into the code so that changes committed to the version control repository kick off automated tests, code analysis and deployments to development or staging environments.
A version control example
Git is the most commonly used version control system, and it is distributed so that software and infrastructure developers can work with a local, offline copy of the code base. Changes to code are committed on a local machine and then pushed to a repository on a server.
Git is completely open source, with numerous products based upon it, such as GitHub. When choosing a product, IT professionals should evaluate whether they need public or private repositories to store source code.
A version control example will show how to work with Git and a GitHub repository. To follow along, create a GitHub account for your Mac, Windows or Linux computer. Sign into GitHub, then close the application; we'll work with Git from the command line in this example to demonstrate the version control workflow.
Open up a terminal or command prompt. Switch to a root directory where you want to store all of your repositories. Each repository will be represented by a subfolder in this location.
To set up the first repository, create a new local folder:
mkdir my-first-repo
Then, switch into that directory:
cd .\my-first-repo\
And initialize the repository:
git init
A message should appear: Initialized empty Git repository. At this point, start adding files to the repository. In this example, we'll add a markdown file that will be rendered as HTML when viewing the repository on GitHub.
To add files, use:
echo "# my-first-repo" >> README.md
The file has been created in the folder, but it's considered untracked at this point by Git. Use the following command to stage the previous change:
git add README.md
With the change staged, we can commit it to the master branch of the repository:
git commit -m "first commit"
Next, sign into GitHub, and create a new repository called my-first-repo. Skip the quick setup, and go back to the command-line interface.
Create a reference to that remote repository from the command line:
Finally, push the local changes in the master branch up to GitHub to create the repository. Authenticate to GitHub after running this command:
git push -u origin master
At this point, other people on your team can clone the repository using git clone.
Version control kicks in once we start to change files. For this version control example, we'll update the README.md with some additional text on a new line. Use any text editor that makes sense for your OS. Run git status to see that the file was modified.Next, stage and commit the change:
git add README.md git commit -m "updated readme"
Once again, push the changes to GitHub:
git push -u origin master
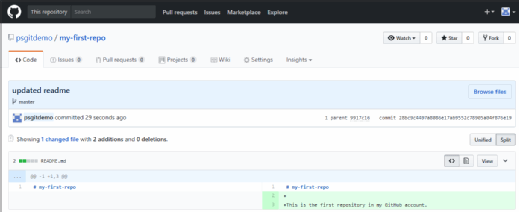
An easy way to compare the changes between the commits is to simply navigate to your repository on GitHub.com and view your latest commit. In the split-screen view shown in the figure, the original file is on the left; on the right is this latest commit, which added a new line and sentence to the file.
This GitHub repository shows two versions of a file, so the user can tell what change was made.
From this point, add infrastructure templates, shell scripts and any other files that you must track and version into this folder. Follow the example version control workflow to stage untracked changes, commit them to the master branch and then push those changes to a remote repository.
Some IT organizations choose to have multiple branches that represent development versions of the files that make up application or infrastructure code.
Take on DevOps
As shown with version control, the key to realizing benefits from DevOps patterns and practices is to apply software development approaches to infrastructure.
To truly embrace DevOps, you must be able to automate everything. Without a public or private cloud platform that provides APIs for automation, you're limited to a manual and potentially error-prone and time-consuming process.
Learn DevOps skills at home
Whether your organization is starting out with DevOps or you want to develop DevOps competency on your own, a home lab is a great way to pick up modern IT skills. Try out GitHub and other tools with the exercises in this DevOps home lab.
Embrace IaC. Private and public cloud platforms provide automation capabilities here as well. For example, in the private cloud space, OpenStack Heat allows IT administrators to define IaC. In the public cloud, Amazon Web Services, Microsoft Azure, Google Cloud Platform and others spin up application environments from infrastructure templates consistently and repeatedly. Configuration management artifacts from products such as Chef, Puppet and Ansible can also work in conjunction with IaC templates. With this approach, all infrastructure and server configuration is completely automated.
With platform automation in place, codify infrastructure and systems configuration. Then, store all the artifacts that are used to automatically provision a given application's resources in a version control repository. This is a good start for any DevOps journey.
Dig Deeper on Systems automation and orchestration