IT automation
What is IT automation?
IT automation is the use of instructions to create a repeated process that replaces an IT professional's manual work in data centers and cloud deployments. Automation software tools, frameworks and appliances conduct the tasks with minimum administrator intervention. The scope of IT automation ranges from single actions to discrete sequences and, ultimately, to an autonomous IT deployment that takes actions based on user behavior and other event triggers.
IT automation is different from orchestration, but the terms are commonly used together. Automation accomplishes a task repeatedly without human intervention. Orchestration is a broader concept in which the user coordinates automated tasks into a cohesive process or workflow for IT and the business.
How IT automation works
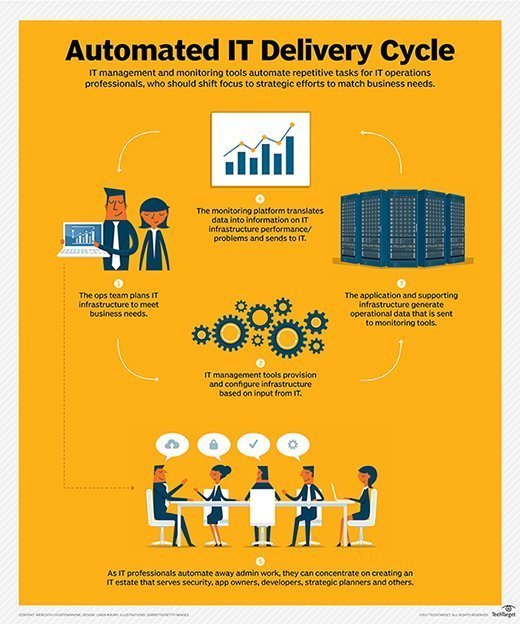
IT automation relies on software tools to define and conduct a prescribed series of detailed actions that are invoked manually or by an external trigger, such as a change in IT capacity demand.
IT automation replaces a series of actions and responses between an administrator and the IT environment. For example, an IT automation platform -- such as Microsoft Windows PowerShell -- combines cmdlets, variables and other components into a script to mimic the series of commands and steps that an administrator would invoke one line at a time through the command-line interface (CLI) to provision a virtual machine (VM) or create a backup process. An administrator can achieve a more complex IT automation outcome by combining multiple scripts into a series. These limited-scope automation processes are most beneficial when they replace a task that an administrator must perform frequently.
Enterprise-class IT infrastructure automation tools trigger actions in response to thresholds and other situational conditions in the IT environment. Advanced IT automation tools oversee the configuration of systems, software and other infrastructure components; recognize unauthorized or unexpected changes; and automatically take corrective actions. For example, if a workload stops responding, this triggers the automated steps to restart it on a different server that has the available capacity to run it. When IT automation is set to enforce a desired state of configurations, the tool detects changes in a server's configuration that are out of spec and restores it to the correct settings.
What IT automation is used for
IT operations managers and IT teams can use IT automation for several tasks, including the following:
- Incident management. Using automation to respond to major incidents helps enterprises restore service faster and with fewer errors. IT automation lets companies reduce the duration and the costs of such incidents for themselves and their customers. For example, an incident management ticket in response to an outage can be quickly created and assigned to the appropriate person or queue through automation.
- Application deployment. Whether organizations use traditional or continuous integration and continuous application deployment approaches, automating essential tasks and capabilities, particularly during testing, can help them successfully deploy their applications. Automation helps companies progress from commit and build to testing to deployment in a more systematic manner, improving efficiency and throughput and reducing the opportunities for human error. Using IT automation, organizations can deploy their applications with confidence, configure necessary services from the outset as well as get their applications and artifacts, such as work that has been documented and stored in a repository so it can be retrieved on-demand, up and running via a common, transparent approach that all their IT staff members can understand.
- Security and compliance. IT operations managers can use automation to define and enforce security, compliance and risk management policies as well as remediate any issues by building them as automated steps throughout their infrastructures. Automation enables IT operations managers to keep security at the front of their IT processes and to be more proactive in their security efforts. Incorporating standardized, automated cybersecurity processes and workflows makes compliance and auditing easier.
Benefits of IT automation
IT automation offers the following benefits:
- Reduced costs. Automating repeatable operational tasks -- such as application deployment and service fulfillment, change and release management and patch management -- can help IT save money by operating more efficiently, making fewer errors and reducing headcount.
- Increased productivity. Workflow automation eliminates manual tasks such as testing, boosting output and freeing up workers to focus on more important projects and be more productive.
- Increased availability. One of IT's most important priorities is to ensure the highest level of system availability. By automating backup and recovery systems, as well as system monitoring and remote communication, IT can significantly reduce downtime and expedite disaster recovery.
- Greater reliability. Automating tedious, repetitive tasks reduces costly errors by eliminating the human factor. This is particularly beneficial in larger networks with numerous operating systems (OSes). By automating repetitive, manual business processes -- such as doing configuration changes on a server or typing a command in the CLI -- IT operations managers can greatly improve reliability, while at the same time relieving workers of these mundane, manual processes.
- Better performance. IT operations managers are being asked to do additional work more quickly and more efficiently. IT automation tools add streamlined processes to optimize performance without having to add more staff.
- Speed. IT requires a significant number of distinct tasks. An administrator can accomplish each task manually, but modern business demands place extraordinary pressure on IT staff to respond quickly to needs across large, complex infrastructures. Humans can't provision and configure workloads in minutes and accomplish all the individual routine tasks required, at any time of day. Automation frees administrators from time spent on routine tasks so they can apply themselves to other value-added projects for the business.
- Intent. An automated system isn't the same thing as an intelligent system; it only knows as much as the human who programmed it can distill into scripts and commands. For example, an email spam filter is an automated IT mechanism designed to filter out unwanted messages. Occasionally, valid email messages end up in the spam folder and unwanted spam email gets past the filter.
- Governance. Different IT administrators perform the same task in different ways, and even the same administrator handles a task differently from one time to the next. For corporate governance and regulatory compliance, an IT automation strategy demonstrates consistency in IT operations, regardless of the administrator on any given day.
- Flexibility. IT processes change over time as the IT infrastructure grows and changes, and technologies and best practices evolve. Automated processes remain static until a person decides to change them. Organizations must have a set workflow to update and revalidate automation processes, including disciplined automation versioning that tracks how tasks change over time.
- Integration and interoperability. IT automation tools must be compatible with systems, software and other elements across potentially diverse IT environments. Ideally, an automation tool should integrate with higher-level orchestration tools to roll tasks together under governed workflows.
Challenges of IT automation
While IT automation has several beneficial use cases, it doesn't always guarantee results. IT staff must be competent and skilled using IT automation tools to translate behaviors into concrete procedural steps.
IT automation can pose the following challenges:
- Increased consequences for errors. An automated error proliferates much more quickly than a manual error. IT automation can also erroneously become a goal in and of itself, regardless of the return on investment (ROI) from the initial setup work to the time saved. While repetition without deviation is a benefit of IT automation, it can also be detrimental. Errors and oversights are easily codified into an automated process, which the automation tool performs as quickly and efficiently as it does the correct steps. If the administrator automates a complex sequence of events and misses a key step or sets a variable incorrectly, that error is repeated until it's caught, remediated and rolled back. One example of an automated error is the 2010 flash crash of the U.S. stock market, which damaged global trade because of an automated computer system with a flawed algorithm.
- High cost of investment. While automation saves time, it requires admins to carefully plan and research each task necessary for the intended workflow and then correctly translate those steps into the automation platform to achieve the desired end state. A company might appoint one or more IT automation managers, replacing or supplementing the role of IT administrator. A substantial upfront investment might also be needed to purchase software and manage the automation. Businesses must ensure that the processes they're trying to automate are going to create a significant ROI. For example, a process that's used repetitively should be automated, compared to a process that only runs once a month.
- Increased chances of detecting failed processes. With automation, there's always a chance that a failed automated process might go undetected. For example, an automation rule that triggers an alert to an IT manager when a certain IT asset is low on resources, might fail and therefore, not be triggered. If automation fails, it increases the risk of detecting failed processes.
- Can become redundant. Any time a change is introduced to IT or software systems, the underlying automation also requires modifications. Updating automation procedures can become time-consuming and expensive.
Different types of automation
Due to the digital transformation, businesses need to expedite and automate business processes that in the past were done manually, such as record keeping or HR onboarding. IT automation and business automation work collectively to help achieve this goal. For example, a company might use IT automation to transition from a legacy paper-driven and time-intensive human resources (HR) onboarding process to an automated and online HR onboarding platform.
The following highlights five types of automation:
- IT automation is a broad term that's often combined with business task automation. An automated IT workflow can accomplish a strictly IT task, such as provisioning additional storage to a VM, or a business task, such as creating a new user account on the corporate email system.
- Service automation uses technology to deliver services in an automated manner. IT automation and service automation are essentially the same.
- Process automation improves workflows, typically in factories and other settings, where the same task or series of tasks occurs repeatedly.
- Business process automation or business automation is the application of IT automation to achieve goals such as increased worker productivity or lower costs of operations.
- Robotic process automation is a software technology that makes it easy to automate digital tasks. Users create software robots called bots that mimic and execute business processes.
Major IT automation vendors
IT automation products appear and evolve rapidly; each product has a specific focus and scope for IT and the business.
Microsoft provides automation in products including System Center 2016 Orchestrator and Service Manager, PowerShell and PowerShell Desired State Configuration.
Other automation vendors offer more narrowly focused product lines. For example, Broadcom provides Server Automation for tasks such as server provisioning and patching, operating system configuration, and automation of storage and application components, client systems and other major enterprise specializations. A similar tool -- BMC Software's BladeLogic Server Automation -- includes preconfigured compliance policies for the Center for Internet Security, Defense Information Systems Agency, Health Insurance Portability and Accountability Act and other regulations.
There are also numerous automation vendors in the software-defined infrastructure market, including Chef, Puppet, SaltStack and HashiCorp. These DevOps IT automation tools support software development and deployment integrated with infrastructure configurations, sometimes called infrastructure as code. The automation capabilities are designed so users can create and support consistent workflows from development to IT operations.
The future of automation
IT automation is hardly a new concept, but the technology is still in its formative stages. Even the most full-featured tools depend on an IT professional or team to develop and maintain discrete automation elements, such as scripts, templates, policies and workflows.
IT automation continues to transform in the following two ways:
AI and machine learning. IT automation will progress to act with greater intelligence and autonomy. IT automation platforms are likely to rely heavily on artificial intelligence (AI) and machine learning technologies. For example, an automation tool can synthesize data on configurations, performance and other information across an IT deployment and process these inputs to discover a normal system operations benchmark, a deviation from which would trigger corrective actions.
Another real-life example is the company Sobereye Inc., which uses AI to improve workplace safety in the construction, mining, transportation and manufacturing industries. By offering a one-minute self-test to employees, it checks for any impairments, such as sleep deprivation, fatigue, medications and drugs to eliminate human errors, which are the biggest contributors to workplace accidents.
Augmented reality. The use of augmented reality (AR) and IT automation is closing workforce gaps in healthcare companies and expediting training for new hires across many other industries. According to the Bureau of Labor Statistics, during the Great Resignation, brought on by the COVID-19 pandemic, millions of Americans quit their jobs. Many companies are using AR to bridge the workforce gap and to get new hires to become productive employees. For example, some warehouse operators have discovered that using AR systems that work with voice commands, such as Google's smart glasses, can shorten the employee's training period by displaying customer order information and product location directly in the wearer's field of vision. Employees might be guided to product shelf arrangements and to each item in the order of picking. Traditionally, this would require performing multiple steps to retrieve the product.
Enterprise automation technologies, including low code, iPaaS and declarative automation, play important factors in improving business processes. Learn about the four key enterprise automation technologies in depth.






